
知识兔小编温馨提醒:这本书的内容比较多,要注意劳逸结合哦

免责声明:
来源于网络,仅用于分享知识,学习和交流!请下载完在24小时内删除。禁用于商业用途!如果您喜欢《云计算与分布式系统:从并行处理到物联网》,请购买正版,谢谢合作。
爱学习,请到知识兔查找资源自行下载!
作者介绍:
Kai Hwang(黄铠),拥有加州大学伯克利分校博士学位。现为美国南加州大学电子工程与计算机科学终身教授,并先后担任清华大学计算机与网络系统方面EMC讲座教授、分布式与云计算IV讲习教授组的首席讲座教授。他曾获中国计算机学会颁发的第1届(2004年)海外杰出学者奖,并于2012年获得国际(IEEE)云计算大会(CloudCom)的终身成就奖。Geoffrey C. Fox,美国印第安纳大学计算机科学、信息与物理学院的杰出教授和院长。他毕业于英国剑桥大学,在并行与分布式计算方面著作丰硕。他曾任职加州理工学院、Syracuse等校,指导毕业了60余位博士生。他目前也是清华大学的IV讲座访问教授。
Jack J. Dongarra,美国田纳西大学电子工程与计算机科学杰出教授,美国橡树岭国家实验室首席研究员。他是世界知名的超级计算机与并行计算专家,也是美国工程院院士,清华大学的IV讲座访问教授。
目录:
出版者的话中文版序
序
前言
第一部分 系统建模、集群化和虚拟化
第1章 分布式系统模型和关键技术
1.1 互联网之上的可扩展计算
1.1.1 互联网计算的时代
1.1.2 可扩展性计算趋势和新的范式
1.1.3 物联网和CPS
1.2 基于网络的系统技术
1.2.1 多核CPU和多线程技术
1.2.2 大规模和超大规模GPU计算
1.2.3 内存、外部存储和广域网
1.2.4 虚拟机和虚拟化中间件
1.2.5 云计算的数据中心虚拟化
1.3 分布式和云计算系统模型
1.3.1 协同计算机集群
1.3.2 网格计算的基础设施
1.3.3 对等网络家族
1.3.4 互联网上的云计算
1.4 分布式系统和云计算软件环境
1.4.1 面向服务的体系结构(SOA)
1.4.2 分布式操作系统趋势
1.4.3 并行和分布式编程模型
1.5 性能、安全和节能
1.5.1 性能度量和可扩展性分析
1.5.2 容错和系统可用性
1.5.3 网络威胁与数据完整性
1.5.4 分布式计算中的节能
1.6 参考文献和习题
第2章 可扩展并行计算集群
2.1 大规模并行集群
2.1.1 集群发展趋势
2.1.2 计算机集群的设计宗旨
2.1.3 基础集群设计问题
2.1.4 Top500超级计算机分析
2.2 计算机集群和MPP体系结构
2.2.1 集群组织和资源共享
2.2.2 节点结构和MPP封装
2.2.3 集群系统互连
2.2.4 硬件、软件和中间件支持
2.2.5 大规模并行GPU集群
2.3 计算机集群的设计原则
2.3.1 单系统镜像特征
2.3.2 冗余高可用性
2.3.3 容错集群配置
2.3.4 检查点和恢复技术
2.4 集群作业和资源管理
2.4.1 集群作业调度方法
2.4.2 集群作业管理系统
2.4.3 集群计算的负载共享设备(LSF)
2.4.4 MOSIX: Linux集群和云的操作系统
2.5 顶尖超级计算机系统的个案研究
2.5.1 Tianhe1A:2010年的世界最快超级计算机
2.5.2 Gray XT5 Jaguar:2009年的领先超级计算机
2.5.3 IBM Roadrunner:2008年的领先超级计算机
2.6 参考文献和习题
第3章 虚拟机和集群与数据中心虚拟化
3.1 虚拟化的实现层次
3.1.1 虚拟化实现的层次
3.1.2 VMM的设计需求和分享商
3.1.3 操作系统级的虚拟化支持
3.1.4 虚拟化的中间件支持
3.2 虚拟化的结构/工具与机制
3.2.1 hypervisor与Xen体系结构
3.2.2 全虚拟化的二进制翻译
3.2.3 编译器支持的半虚拟化技术
3.3 CPU、内存和I/O设备的虚拟化
3.3.1 虚拟化的硬件支持
3.3.2 CPU虚拟化
3.3.3 内存虚拟化
3.3.4 I/O虚拟化
3.3.5 多核处理器的虚拟化
3.4 虚拟集群和资源管理
3.4.1 物理集群与虚拟集群
3.4.2 在线迁移虚拟机的步骤与性能影响
3.4.3 内存、文件与网络资源的迁移
3.4.4 虚拟集群的动态部署
3.5 数据中心的自动化与虚拟化
3.5.1 数据中心服务器合并
3.5.2 虚拟存储管理
3.5.3 虚拟化数据中心的云操作系统
3.5.4 虚拟化数据中心的可信管理
3.6 参考文献与习题
第二部分 云平台、面向服务的体系结构和云编程
第4章 构建在虚拟化数据中心上的云平台体系结构
4.1 云计算和服务模型
4.1.1 公有云、私有云和混合云
4.1.2 云生态系统和关键技术
4.1.3 基础设施即服务(IaaS)
4.1.4 平台即服务 (PaaS) 和软件即服务(SaaS)
4.2 数据中心设计与互连网络
4.2.1 仓库规模的数据中心设计
4.2.2 数据中心互连网络
4.2.3 运送集装器的模块化数据中心
4.2.4 模块化数据中心的互连
4.2.5 数据中心管理问题
4.3 计算与存储云的体系结构设计
4.3.1 通用的云体系结构设计
4.3.2 层次化的云体系结构开发
4.3.3 虚拟化支持和灾难恢复
4.3.4 体系结构设计挑战
4.4 公有云平台:GAE、AWS和Azure
4.4.1 公有云及其服务选项
4.4.2 谷歌应用引擎(GAE)
4.4.3 亚马逊的Web服务(AWS)
4.4.4 微软的Windows Azure
4.5 云间的资源管理
4.5.1 扩展的云计算服务
4.5.2 资源配置和平台部署
4.5.3 虚拟机创建和管理
4.5.4 云资源的全球交易
4.6 云安全与信任管理
4.6.1 云安全的防御策略
4.6.2 分布式入侵/异常检测
4.6.3 数据和软件保护技术
4.6.4 数据中心的信誉指导保护
4.7 参考文献与习题
第5章 面向服务的分布式体系结构
5.1 服务和面向服务的体系结构
5.1.1 REST和系统的系统
5.1.2 服务和Web服务
5.1.3 企业多层体系结构
5.1.4 网格服务和OGSA
5.1.5 其他的面向服务的体系结构和系统
5.2 面向消息的中间件
5.2.1 企业总线
5.2.2 发布-订阅模型和通知
5.2.3 队列和消息传递系统
5.2.4 云或网格中间件应用
5.3 门户和科学网关
5.3.1 科学网关样例
5.3.2 科学协作的HUBzero平台
5.3.3 开放网关计算环境(OGCE)
5.4 发现、注册表、元数据和数据库
5.4.1 UDDI和服务注册表
5.4.2 数据库和订阅-发布
5.4.3 元数据目录
5.4.4 语义Web和网格
5.4.5 作业执行环境和监控
5.5 面向服务的体系结构中的工作流
5.5.1 工作流的基本概念
5.5.2 工作流标准
5.5.3 工作流体系结构和规范
5.5.4 工作流运行引擎
5.5.5 脚本工作流系统Swift
5.6 参考文献与习题
第6章 云编程和软件环境
6.1 云和网格平台的特性
6.1.1 云的功能和平台的特性
6.1.2 网格和云的公共传统特性
6.1.3 数据特性和数据库
6.1.4 编程和运行时支持
6.2 并行和分布式编程范式
6.2.1 并行计算和编程范式
6.2.2 MapReduce、Twister和迭代MapReduce
6.2.3 来自Apache的Hadoop软件库
6.2.4 微软的Dryad和DryadLINQ
6.2.5 Sawzall和Pig Latin高级语言
6.2.6 并行和分布式系统的映射应用
6.3 GAE的编程支持
6.3.1 GAE编程
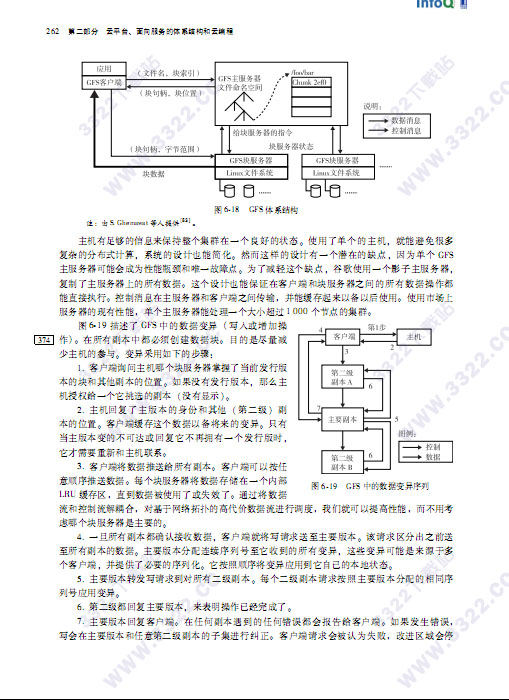
6.3.2 谷歌文件系统(GFS)
6.3.3 BigTable——谷歌的NOSQL系统
6.3.4 Chubby——谷歌的分布式锁服务
6.4 亚马逊AWS与微软Azure中的编程
6.4.1 亚马逊EC2上的编程
6.4.2 亚马逊简单存储服务(S3)
6.4.3 亚马逊弹性数据块存储服务(EBS)和SimpleDB
6.4.4 微软Azure编程支持
6.5 新兴云软件环境
6.5.1 开源的Eucalyptus和Nimbus
6.5.2 OpenNebula、Sector/Sphere和Open Stack
6.5.3 Manjrasoft Aneka云和工具机
6.6 参考文献与习题
第三部分 网格、P2P和未来互联网
第7章 网格计算系统和资源管理
.......
第8章 对等计算和覆盖网络
.......
第9章 普适云计算、物联网与社会网络
.......
索引
精彩书摘:
......用户可能会遇到一些延迟或者丢失在最后检查点前未保存的部分数据。
故障切换集群故障切换可能是目前商业应用集群所需的最重要特征。当一个组件失效时,该技术允许剩余系统接管之前由失效组件分享的服务。故障切换机制必须分享一些功能,如失效诊断、失效通知和失效恢复。失效诊断是指失效以及导致该失效的故障组件位置的检测。一种常用的技术是使用心跳消息,集群节点发送心跳消息给对方。如果系统没有接收到某个节点的心跳消息,那么可以判定节点或者网络连接失效了。
例2.8双网络集群的失效诊断和恢复
集群使用两个网络连接其节点。其中一个节点被指定为主节点(master node)。每个节点都有一个心跳维护进程,该进程通过两个网络周期性(每10秒)发送心跳消息至主节点。如果主节点没有接收到某节点的心跳(10秒)消息,那么将认为探测到失效并会作出如下诊断:
节点到两个网络之一的连接失效,如果主节点从一个网络接收到该节点的心跳消息,但从另一个却没有接收到。
节点发生故障,如果主节点从两个网络都没有接收到心跳消息。这里假设两个网络同时失效的几率忽略不计。
示例中的失效诊断很简单,但它有若干缺陷。如果主节点失效,怎么办?10秒的心跳周期是太长。还是太短?如果心跳消息在网络中丢失了(例如,由于网络拥塞),怎么办?该机制能否适用于数百个节点?实际的高可用性系统必须解决这些问题。一种常用的技术是使用心跳消息携带负载信息,当主节点接收到某个节点的心跳消息时,它不仅了解该节点存活着,而且知道该节点的资源利用率等情况。这些负载信息对于负载均衡和作业管理是很有用的。
失效一旦被诊断,系统将通知需要知道该失效的组件。失效通知是必要的,因为不仅仅只有主节点需要了解这类信息。例如,某个节点失效,DNS需要被通知,以至不会有更多的用户连接到该节点。资源管理器需要重新分配负载,同时接管失效节点上的剩余负载。系统管理员也需要被提醒,这样他能够进行适当的操作来修复失效节点。
恢复机制
失效恢复是指接管故障组件负载的必需动作。恢复技术有两种类型:在向后恢复中,集群上运行的进程持续地存储一致性状态(称为检查点)到稳定的存储。失效之后,系统被重新配置以隔离故障组件、恢复之前的检查点,以及恢复正常的操作。这称为回滚。
向后恢复与应用无关、便携,相对容易实现,已被广泛使用。然而,回滚意味着浪费了之前执行结果。如果执行时间是至关重要的,如在实时系统中,那么回滚时间是无法容忍的,应该使用向前恢复机制。在这个机制下,系统并不回滚至失效前的检查点。相反,系统利用失效诊断信息重建一个有效的系统状态,并继续执行。向前恢复是应用相关的,并且可能需要额外的硬件。
例2.9 MTTF、MTTR和失效成本分析
考虑一个基本没有可用性支持的集群。当一个节点失效,下面一系列事件将会发生:
1.整个系统被关闭和断电。
2.如果硬件失效,故障节点被替换。
3.该系统通电和重启。
4.用户应用程序被重新装载,并从开始重新运行。
假设集群中的某个节点每100小时发生一次故障。集群的其余部分不会发生故障。步骤1~3需要花费2小时。一般来说,步骤4的平均时间也是2小时。该集群的可用性是多少?如果每小时的停机损失为82 500美元,每年的失效损失是多少?解 集群的MTTF是100小时,MTTR是2+2=4小时。根据表2—5,可用性为100/104=96.15%。这相当于每年337小时的停机时间,失效损失为82 500美元×337,即超过2 700万美元。
……
使用说明:
方法一:1、下载并解压,得出pdf文件
2、如果打不开本文件,请务必在知识兔选择一款阅读器下载
3、安装后,在打开解压得出的pdf文件
4、双击进行阅读
方法二:
1、在手机里下载知识兔中的阅读器和百度网盘
2、直接将pdf传输到百度网盘
3、用阅读器打开即可阅读
下载体验